Language Modeling
这一部分的详细内容在我的CS224N系列笔记中有更好的说明,这里只是梗概性地讲了一下。 4 - Language Models and RNN LM的进化path: 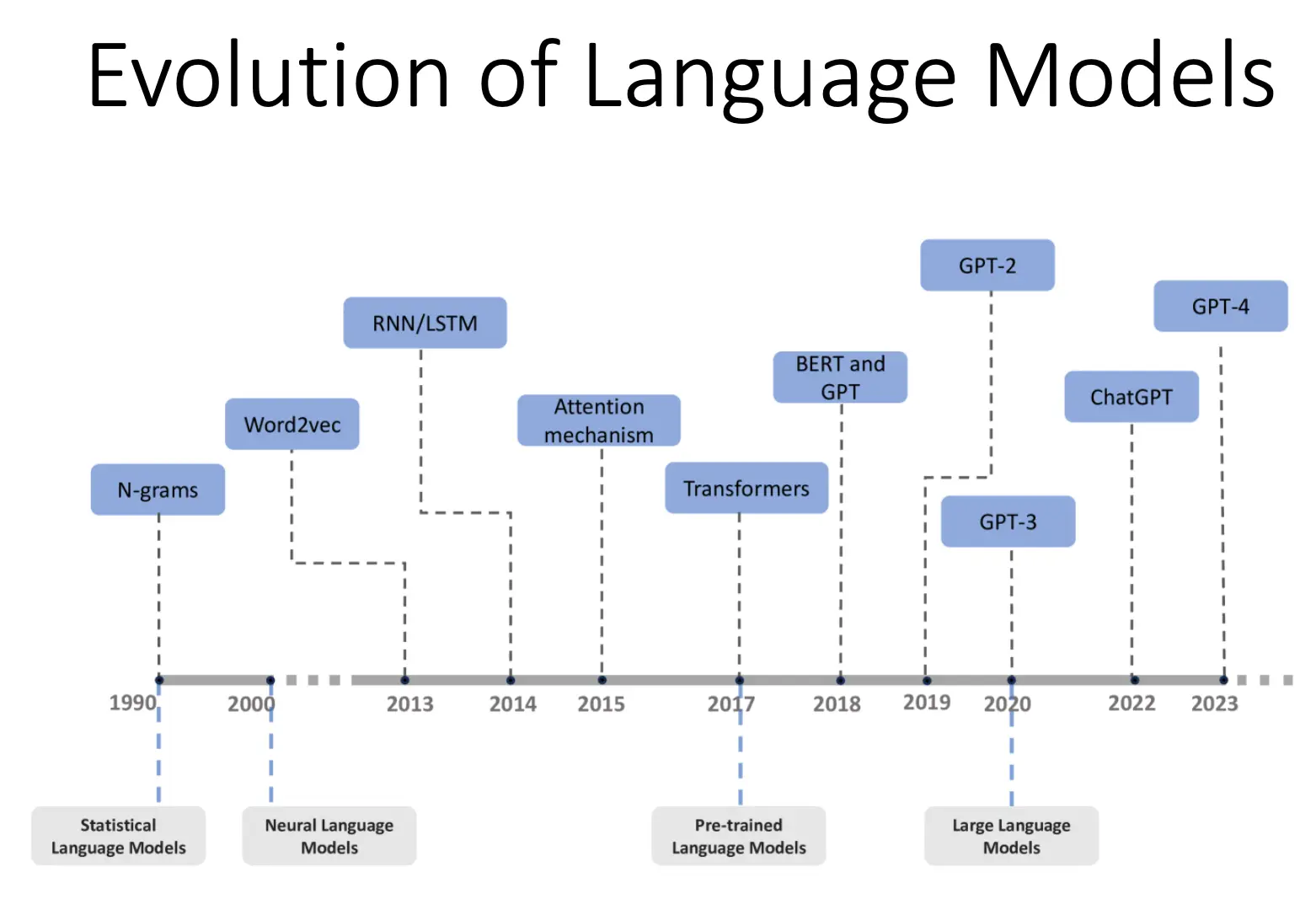
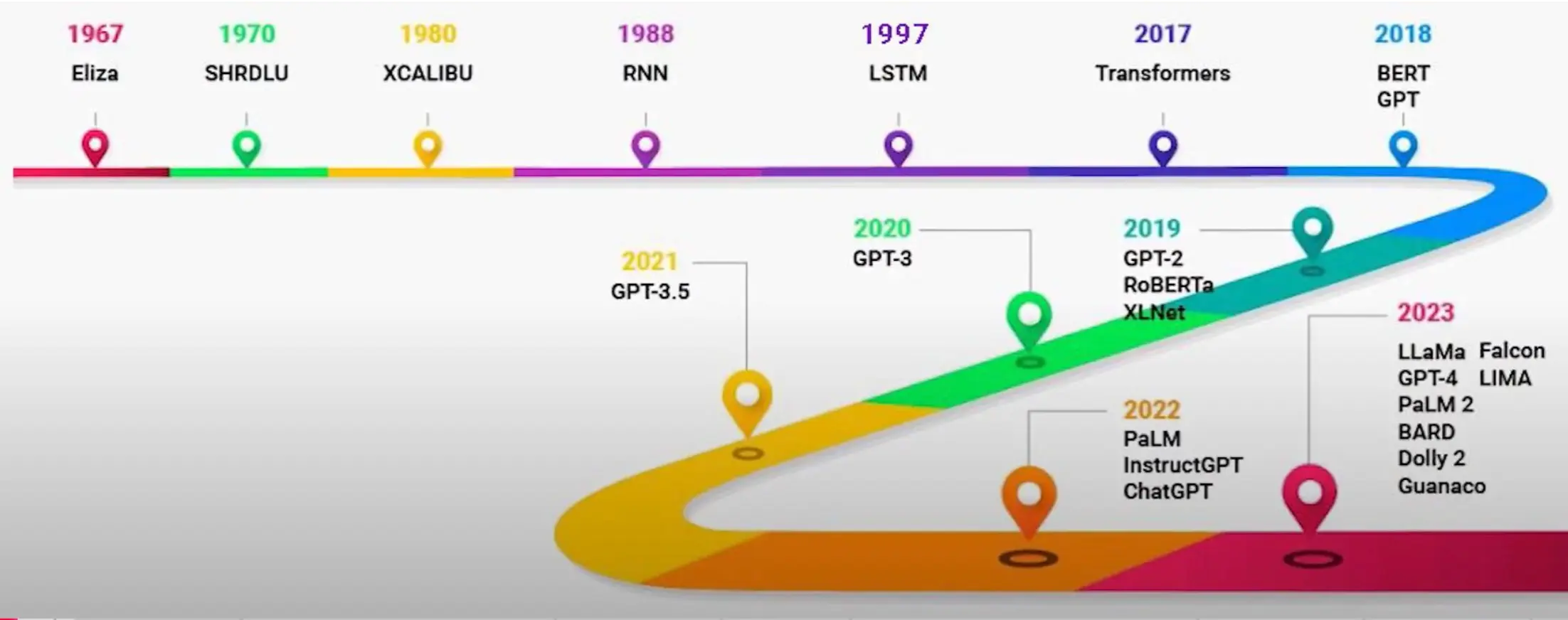
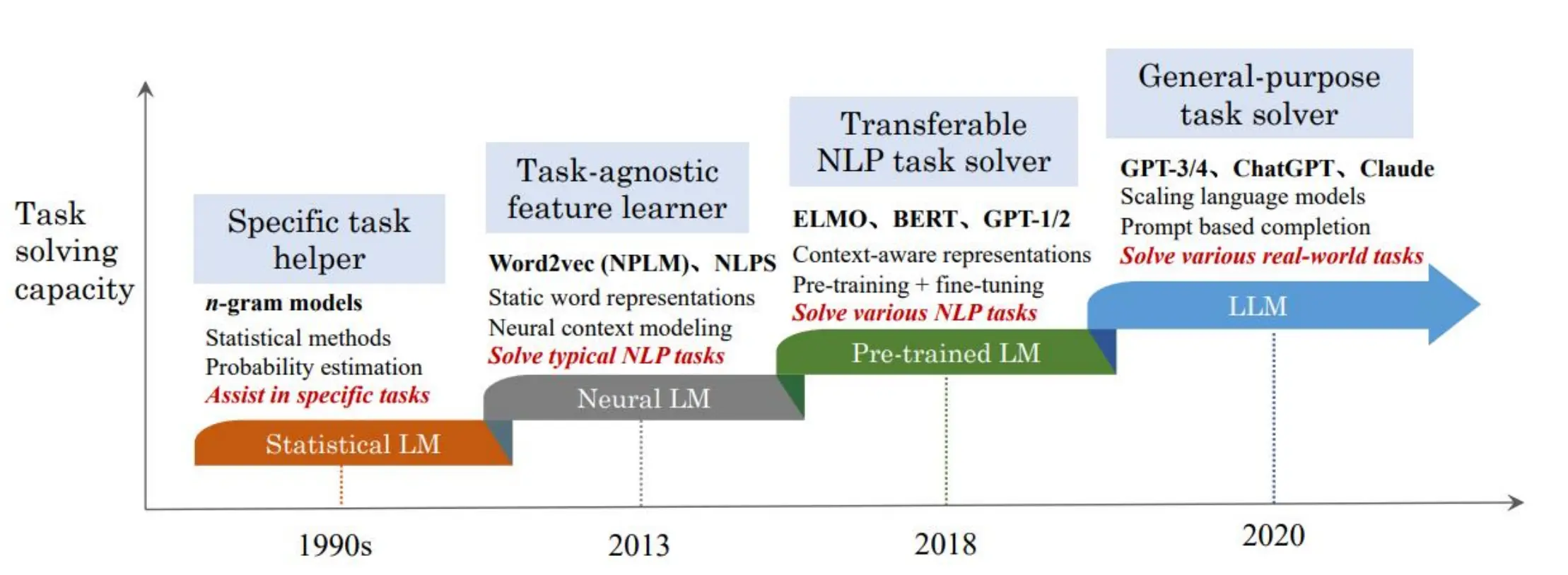
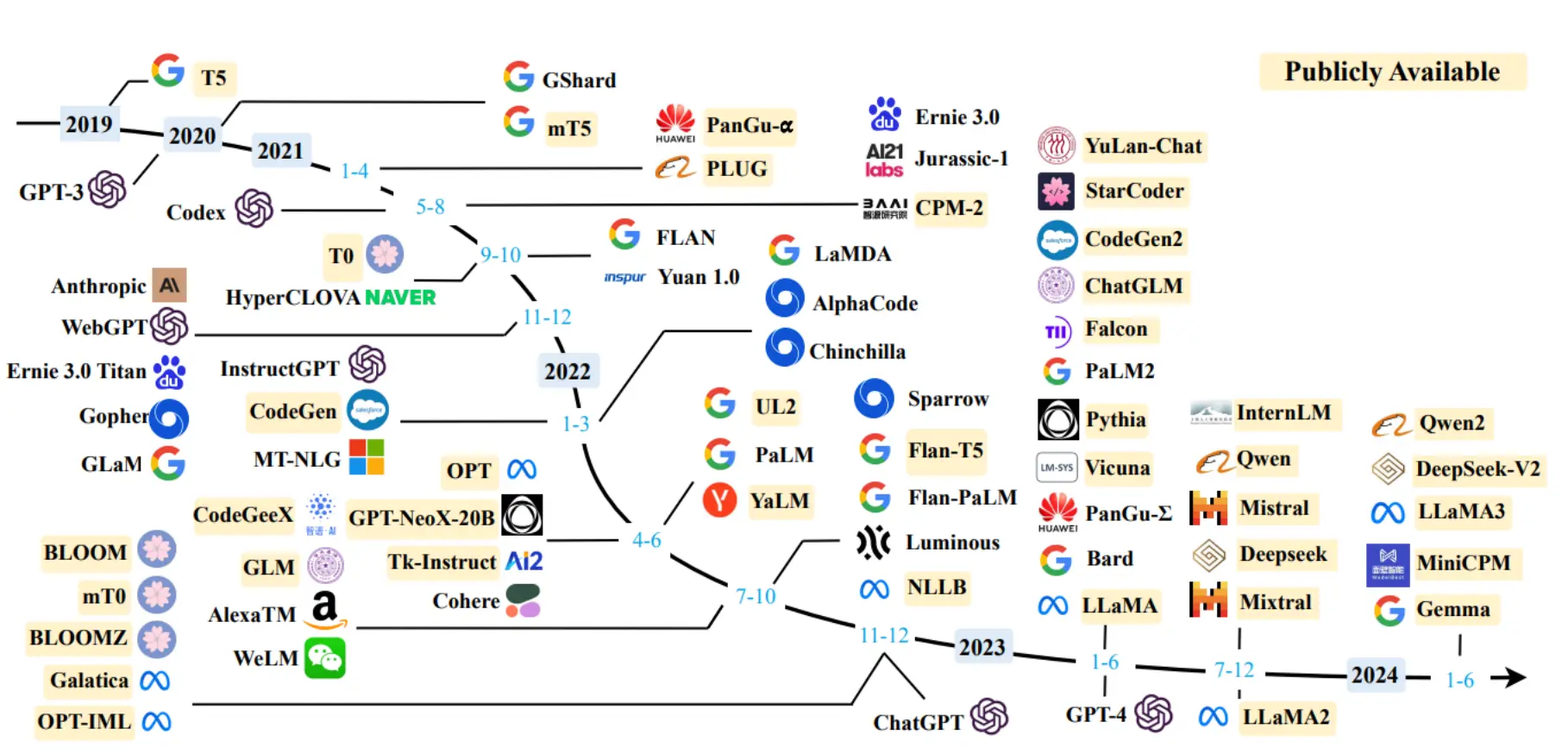
语言模型
可以预测即将出现的单词的模型 语言模型的一般任务:
- 给整句算概率,也就是“这整串词出现的概率有多大”,可用于评价句子“合理”与否、或在机器翻译里做束搜索(beam search)打分。:
- 预测下一个词,
这正是“给前文,猜下一个词会是什么”的任务,是自回归语言模型常见的训练/推理形式。
这两个目标其实等价,因为若你能准确算出每个条件概率,就能乘起来得到整句概率:
反之,只要建了一个能预测下一个词的模型,就能通过累乘得到整句的概率。 然而,用简单的数数相除,也就是频率估计概率在LM中是行不通的:
这是因为,可能的句子数量爆炸,你没法统计。 根据链式法则,我们可以知道:
但是这还是有点长。然而,根据俄国数学家 Andrei Markov 提出——我们可以假设“当前状态只依赖有限个历史状态”。在语言模型里,最常见的就是一阶马尔可夫(bigram):
也就是说,“blue”出现的概率,只看它前面紧邻的一个词“beautifully”,而忽略更远的上下文。而如果是k阶马尔可夫,那么就是
这正好可以推广到n-gram。 有了一阶马尔可夫(bi-gram),我们就可以根据频率估计概率了: 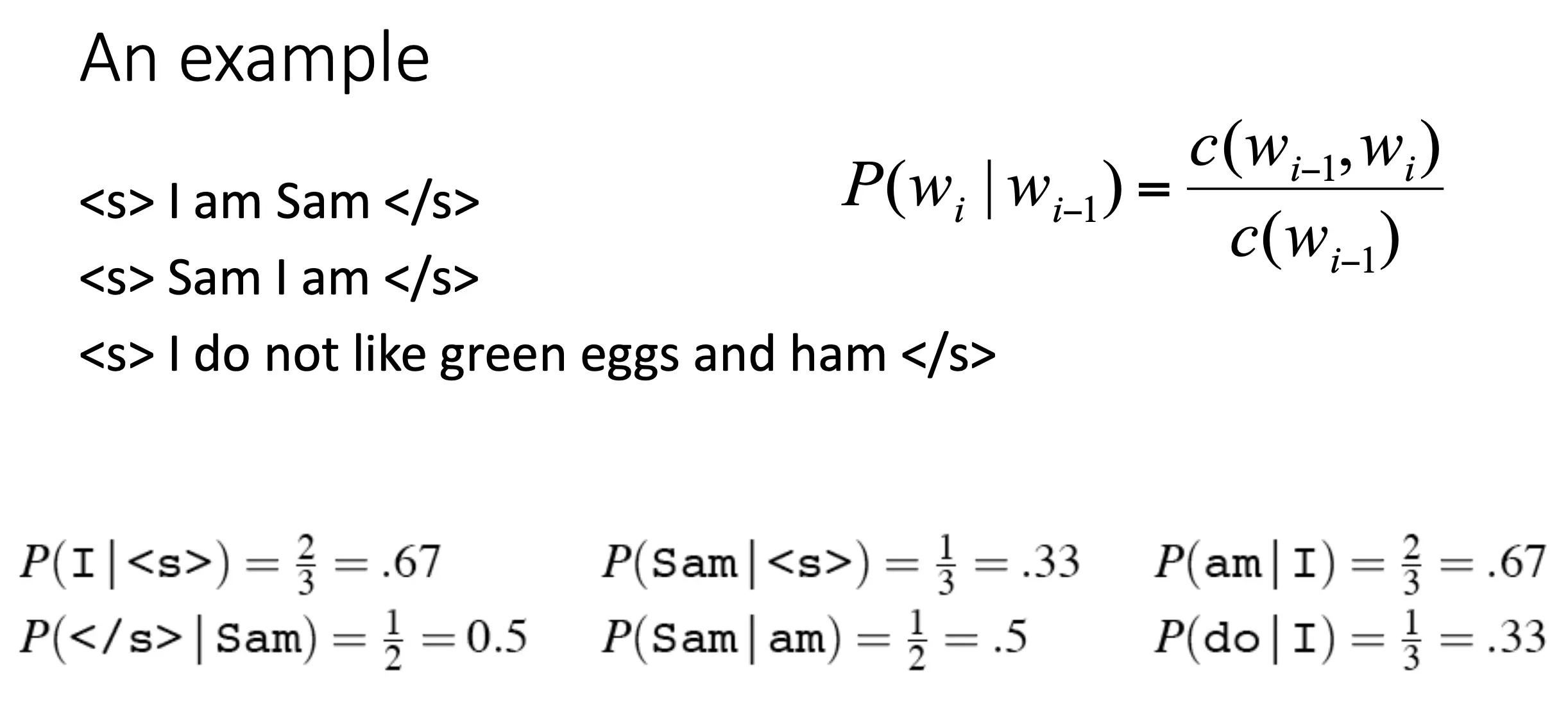 推广到n-gram也可以,但是有问题:N-grams 无法处理长距离依赖关系。解决方法就是:Neural Language Models
推广到n-gram也可以,但是有问题:N-grams 无法处理长距离依赖关系。解决方法就是:Neural Language Models
评估LM
Extrinsic (in-vivo) Evaluation
在任务中看效果
Intrinsic (in-vitro) evaluation
Expensive, time-consuming,不泛化到其他任务 perplexity
Perplexity
这个metric我在CS224N中提过:4 - Language Models and RNN 困惑度可以理解为“平均每一步模型要在多少种可能的下一个词中做选择”;越偏好正确的下一个词,困惑度就越低。 


Auto-Regressive Language Models
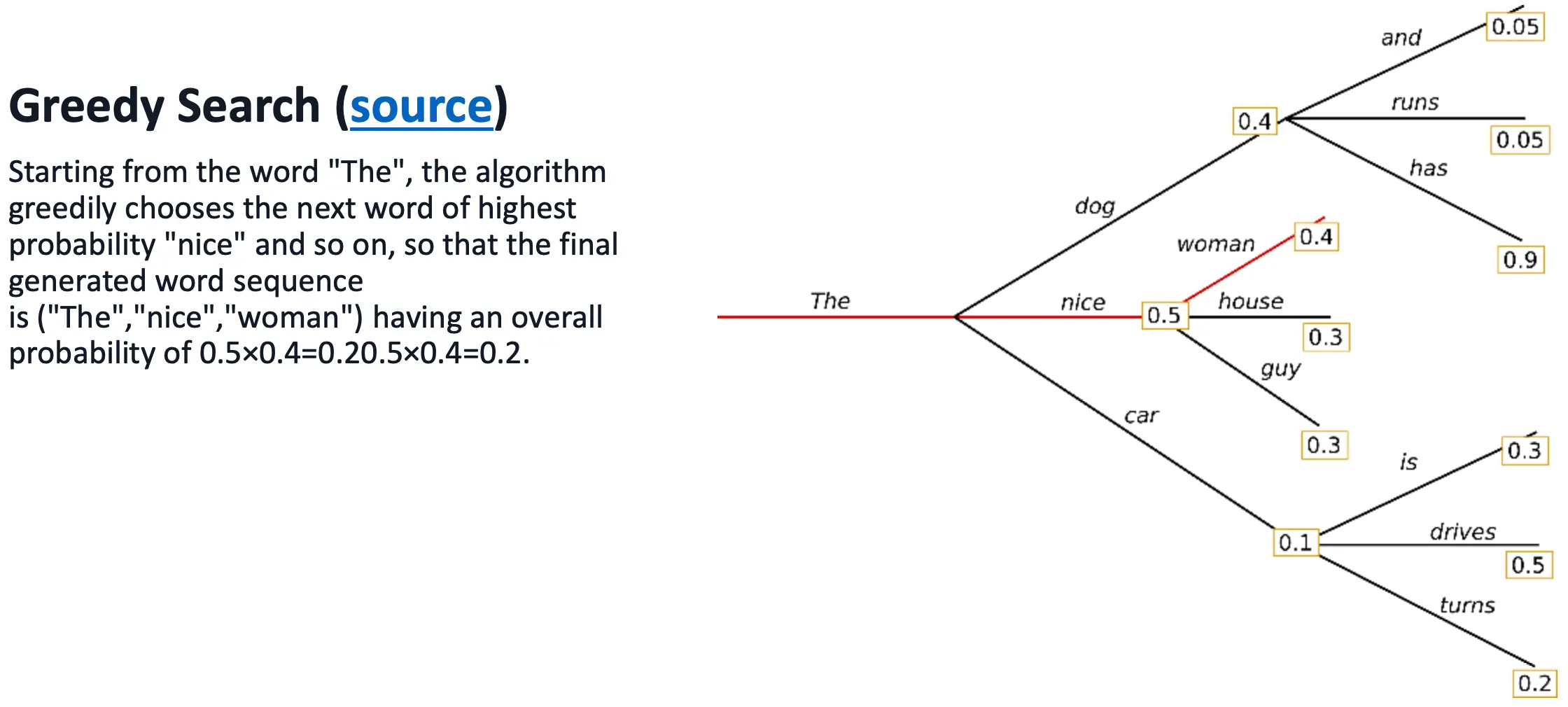
Greedy Search
Beam Search
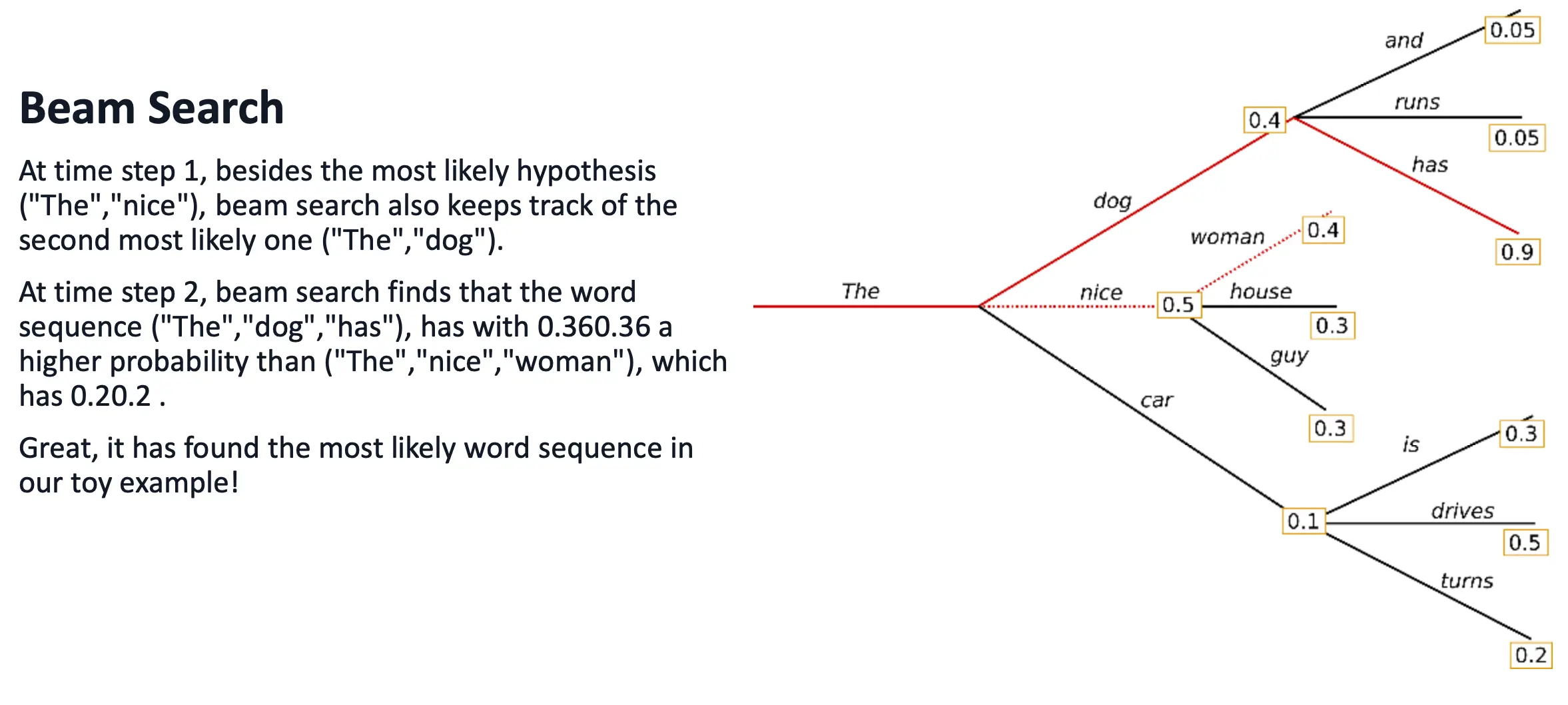 Beam Search往远看一步,也就是直接看两步。
Beam Search往远看一步,也就是直接看两步。
- “nice” → “woman” (0.5×0.4=0.20), → “house” (0.5×0.3=0.15), …
- “dog” → “has” (0.4×0.9=0.36), → “runs” (0.4×0.05=0.02), …
Sampling
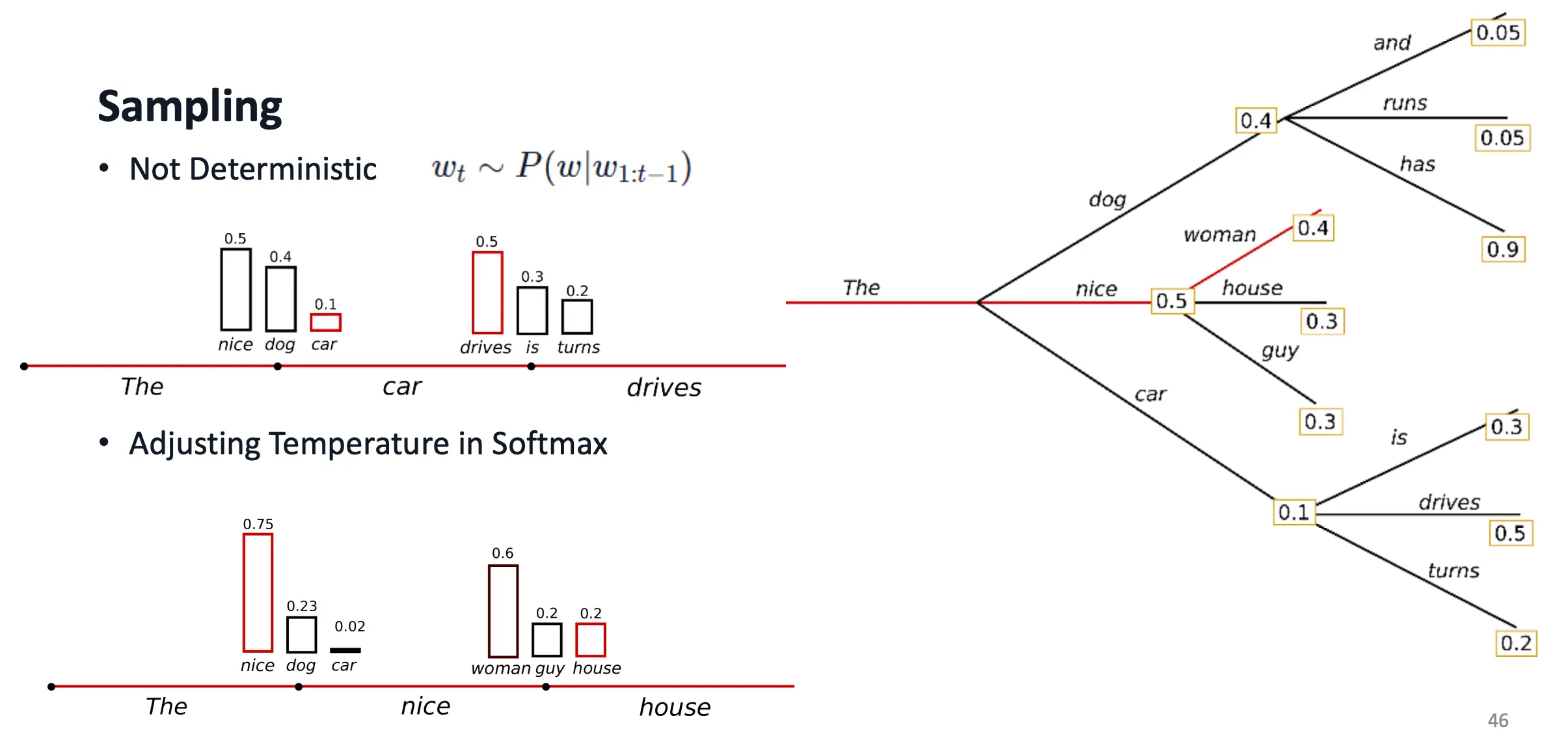 采样:不是总选概率最大的词,而是从这个分布里随机抽样。 当然也可以温度调节,在 softmax 前除以一个温度参数 T:
采样:不是总选概率最大的词,而是从这个分布里随机抽样。 当然也可以温度调节,在 softmax 前除以一个温度参数 T:
- **T<1:增强高概率词(更“贪心”);
- T>1:让分布更平缓,增加多样性。 当温度降低时,“nice” 的采样概率从 0.5 提升到 0.75,其他词相应下降。
Top-K Sampling
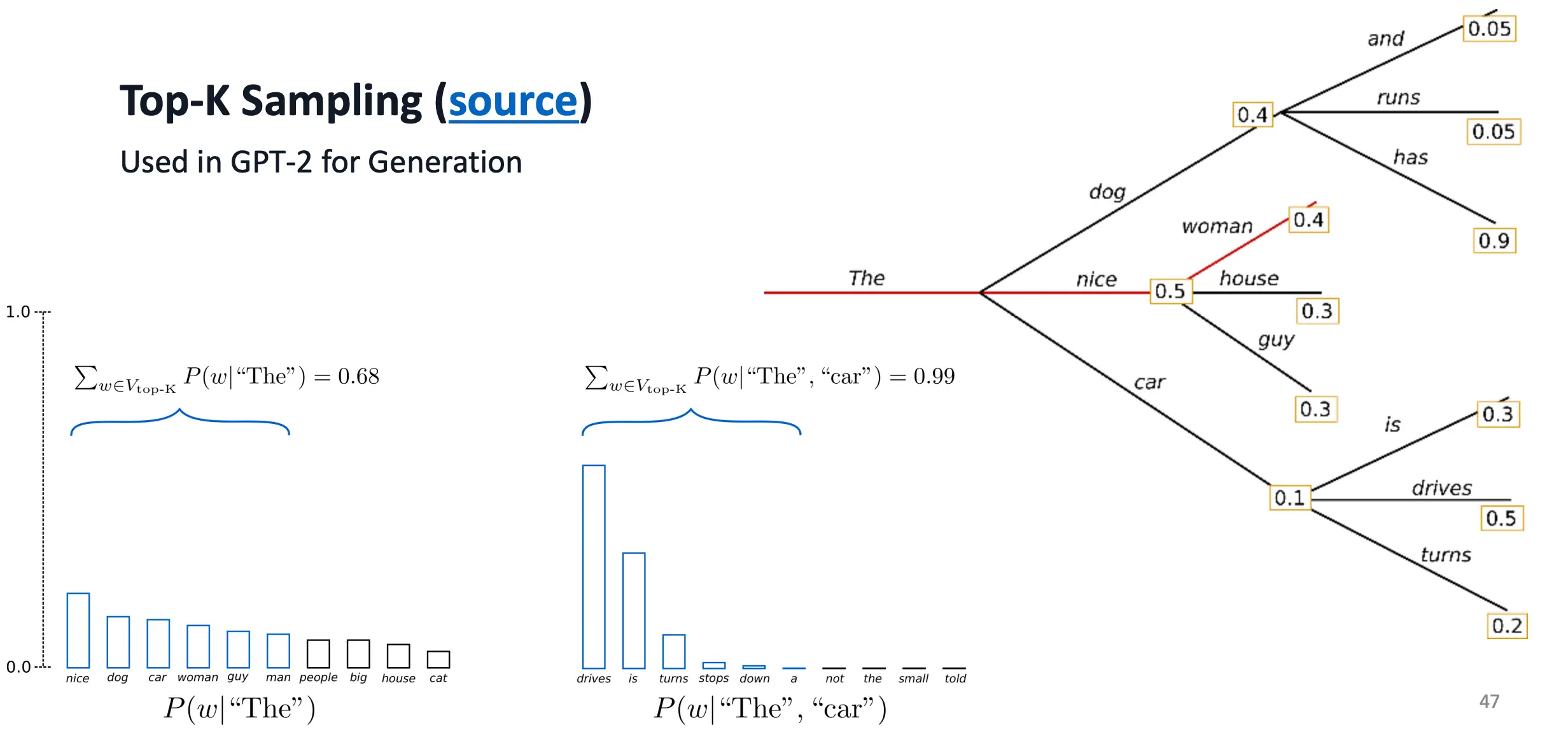 Top-K 采样(固定词表大小),在每一步,只保留概率 最高的 K 个 词,把其他所有词的概率都置为 0,再对这 K 个词重新做归一化然后随机抽样。 固定保留前 K 个词
Top-K 采样(固定词表大小),在每一步,只保留概率 最高的 K 个 词,把其他所有词的概率都置为 0,再对这 K 个词重新做归一化然后随机抽样。 固定保留前 K 个词
Top-P Sampling
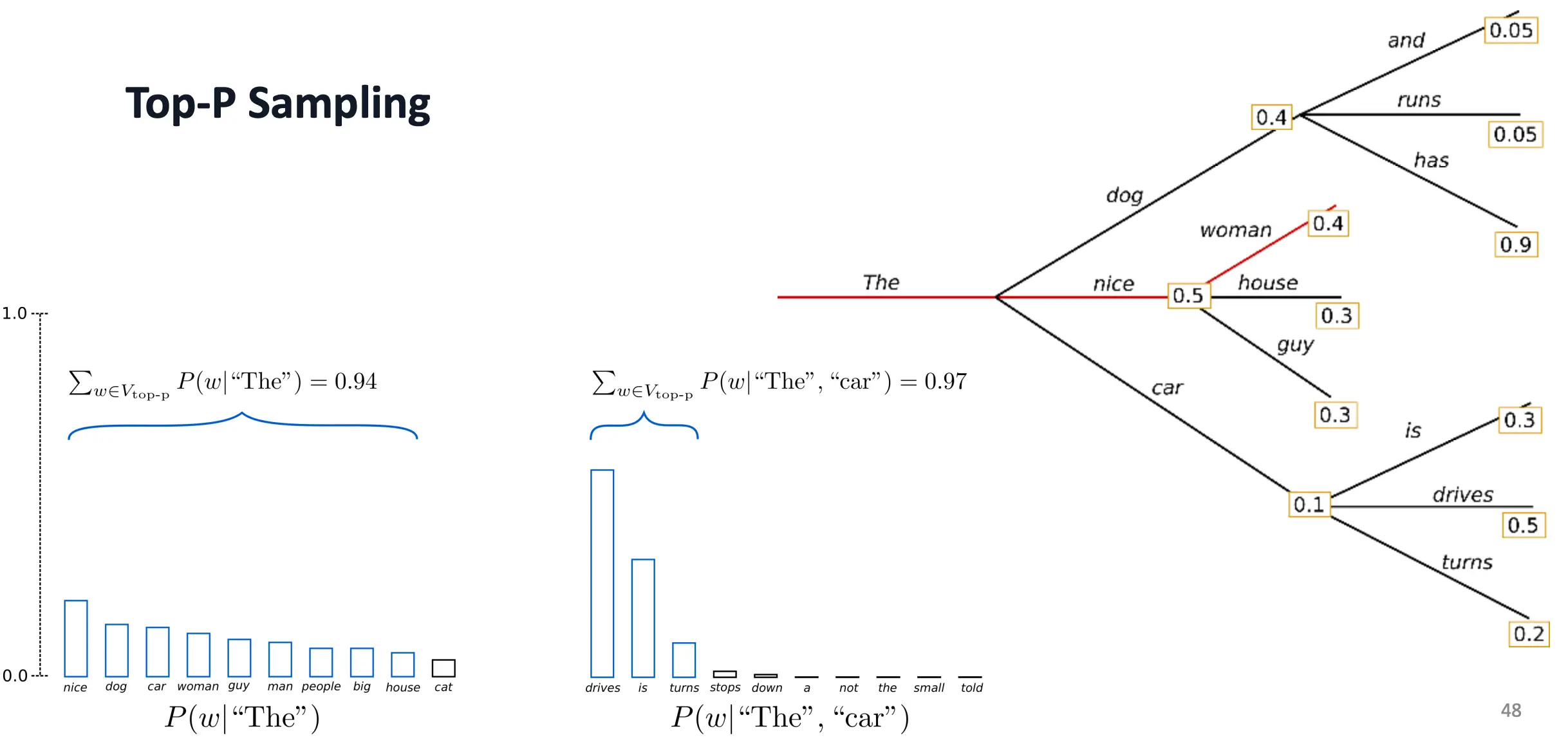 在每一步,不再固定保留 K 个词,而是找到最小的词集 Vtop-p使得它们的累积概率 ≥ p(例如 0.9)。然后只在这个动态大小的集合里做随机采样。 保留最少的词,直到累积概率 ≥ p
在每一步,不再固定保留 K 个词,而是找到最小的词集 Vtop-p使得它们的累积概率 ≥ p(例如 0.9)。然后只在这个动态大小的集合里做随机采样。 保留最少的词,直到累积概率 ≥ p
Word Embedding
N-gram 模型——比如 bigram、trigram——本质上是在训练语料里 “数数再除”,把每个前缀后面跟着每个词的频率都记下来。 它完全依赖训练语料中的出现情况——只有在训练集中见过的上下文-词对才有非零概率;如果测试时遇到和训练时分布不完全一样的语言,模型就会“毫无准备”地崩溃——因为它没见过、就给 0 概率!
这种情况perplexity都算不出来。
- 经典的 N-gram 平滑(加一、Katz 回退、Kneser–Ney……)都是为了解决“零概率”问题,让未见过的组合也能分到一点“默认”质量。
- 但这些方法往往需要手工调参,且在高维(大上下文长度、大词表)时效果也有限。
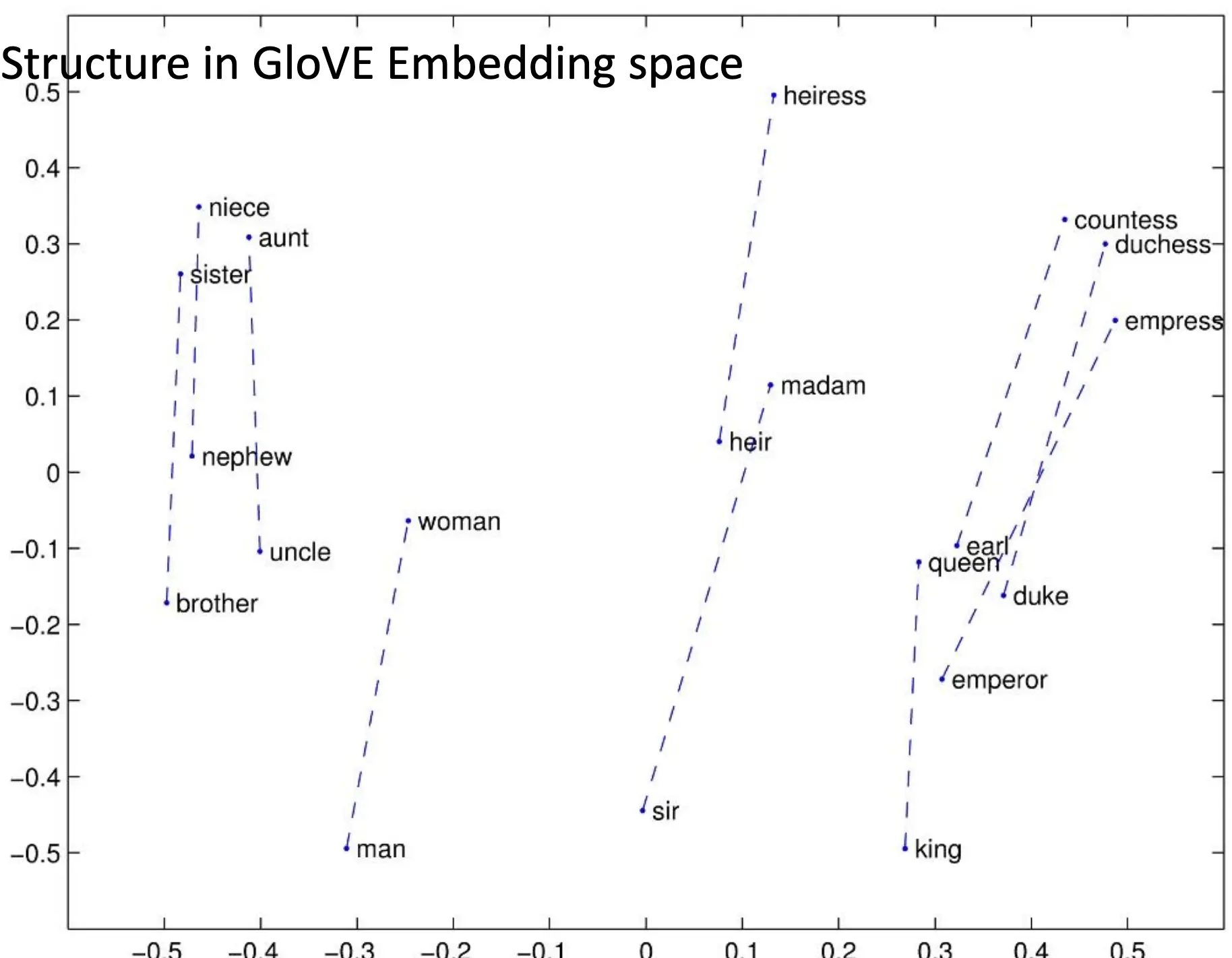
所以,我们要引入词向量/Embedding 来救场。用连续的、低维的实数向量来表示每个词,使得语义或用法相似的词在向量空间里“挨得近”
常用的可以下载到的静态模型:Word2vec,GloVe。
Neural Architectures for Language Modeling
这部分在 8 - Pretraining 中详细讨论过。 路线:
- Feed Forward Network
- Recurrent NN
- LSTM RNN
- Stacked LSTM NN
- Stacked Bidirectional LSTMs
- Transformer
- Decoders
- GPT, Claude,Llama
- Encoders
- BERT family
- Encoder-decoders
- Flan-T5, Whisper
- Decoders
BERT - Encoder only
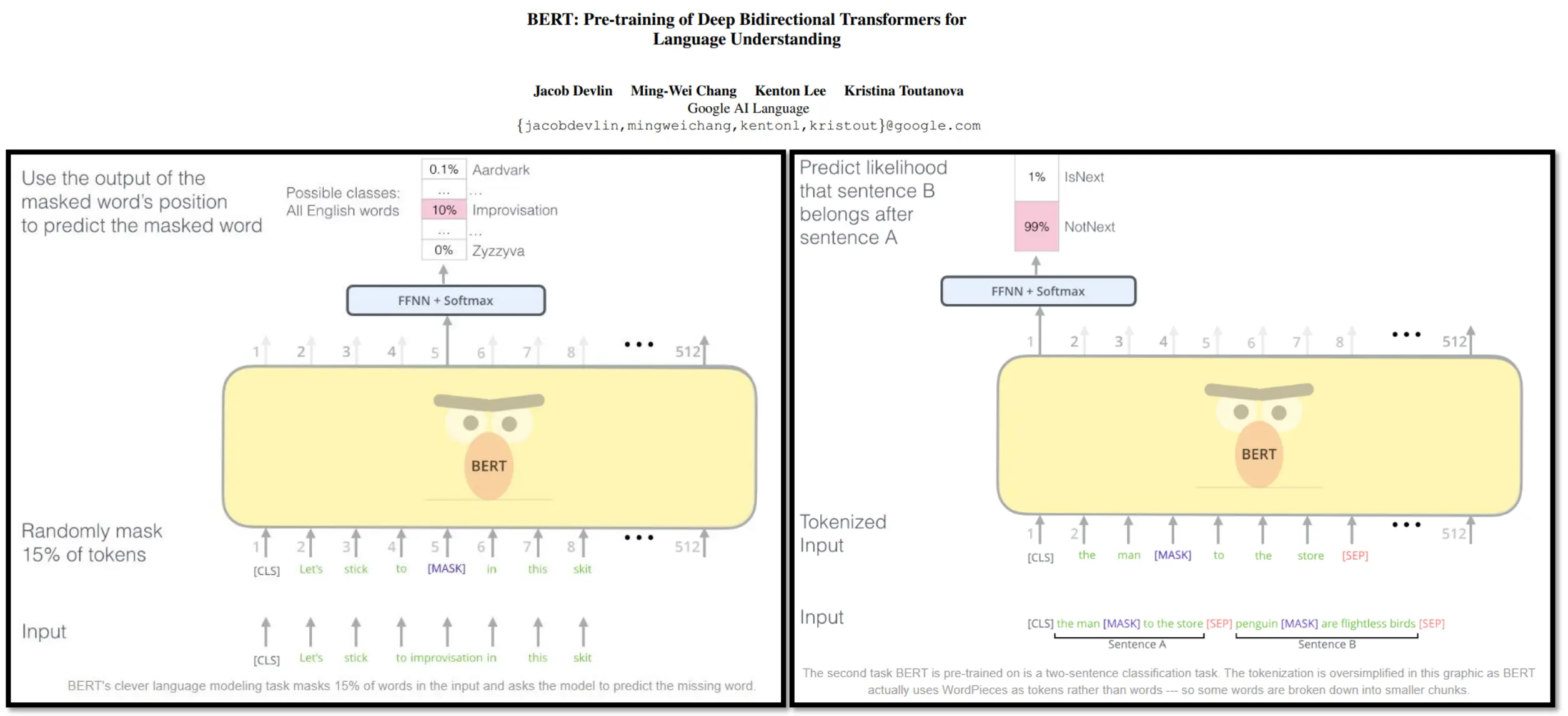 BERT能生成吗?可填空,却不擅长“续写”。可以变通,让BERT生成,改成填空模式即可。 下面例子是用 BERT 做句子嵌入,再接一个简单情绪分类器: 首先用DistilBERT 把每个句子映射成一个 768 维 的向量表示:
BERT能生成吗?可填空,却不擅长“续写”。可以变通,让BERT生成,改成填空模式即可。 下面例子是用 BERT 做句子嵌入,再接一个简单情绪分类器: 首先用DistilBERT 把每个句子映射成一个 768 维 的向量表示: 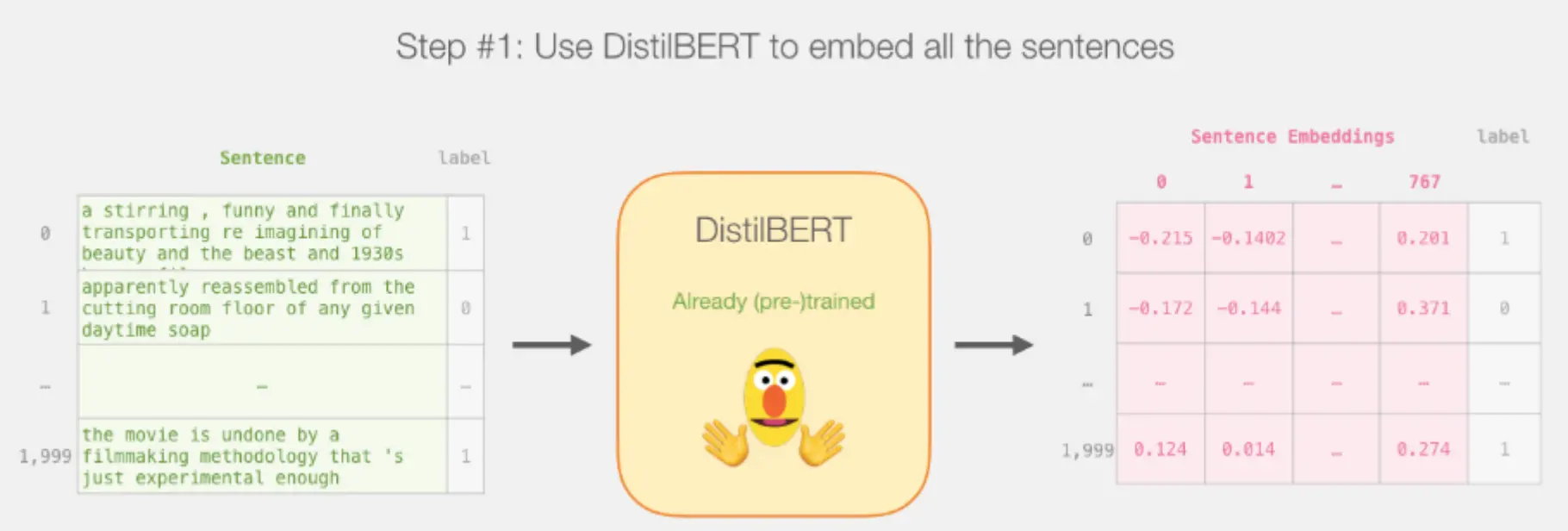 然后划分训练集 / 测试集:
然后划分训练集 / 测试集: 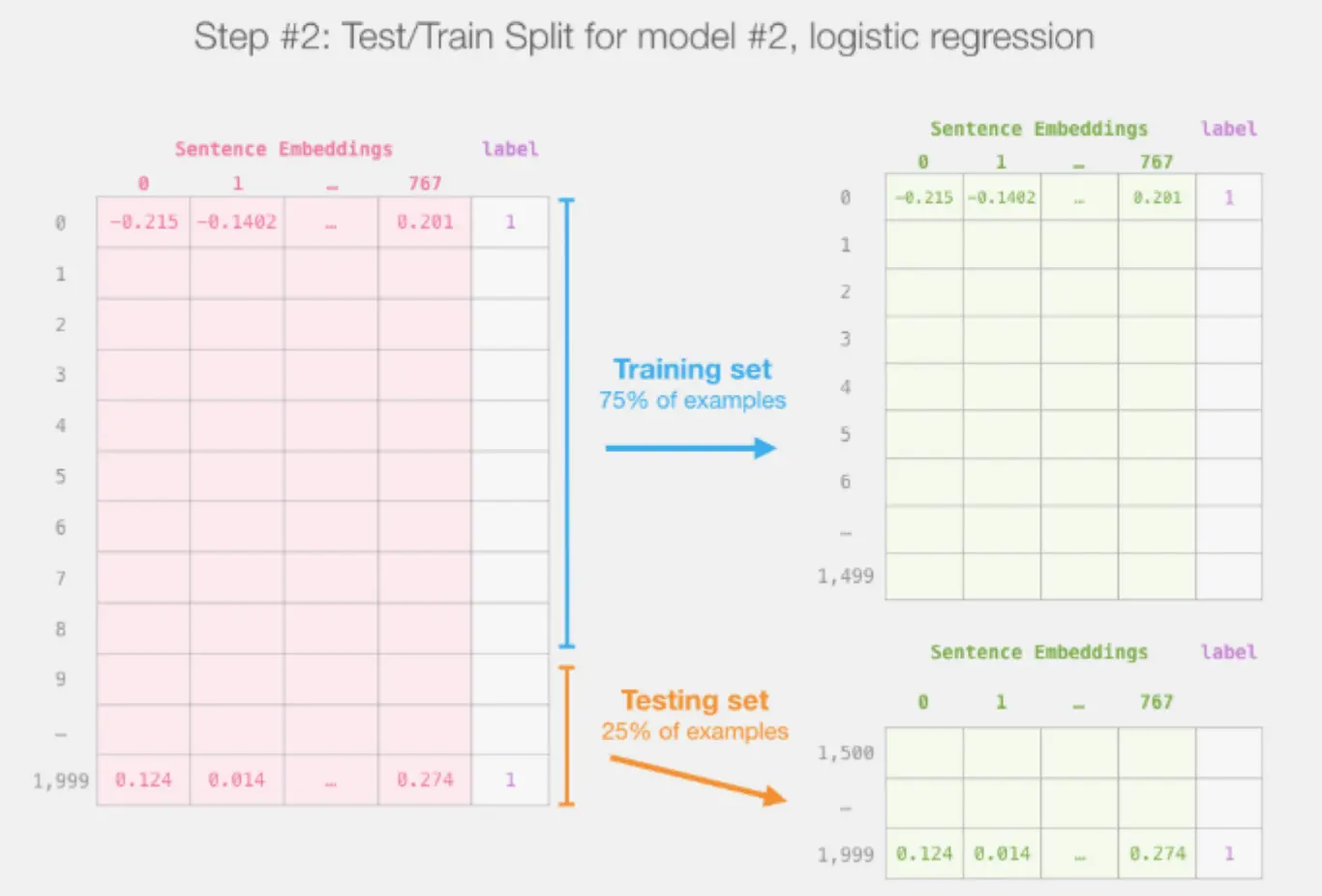 用一个轻量级的 scikit-learn
用一个轻量级的 scikit-learn LogisticRegression 训练集的嵌入向量 + 对应标签。 最优化一个二分类的对数损失,让模型学会从 768 维特征预测正负面。 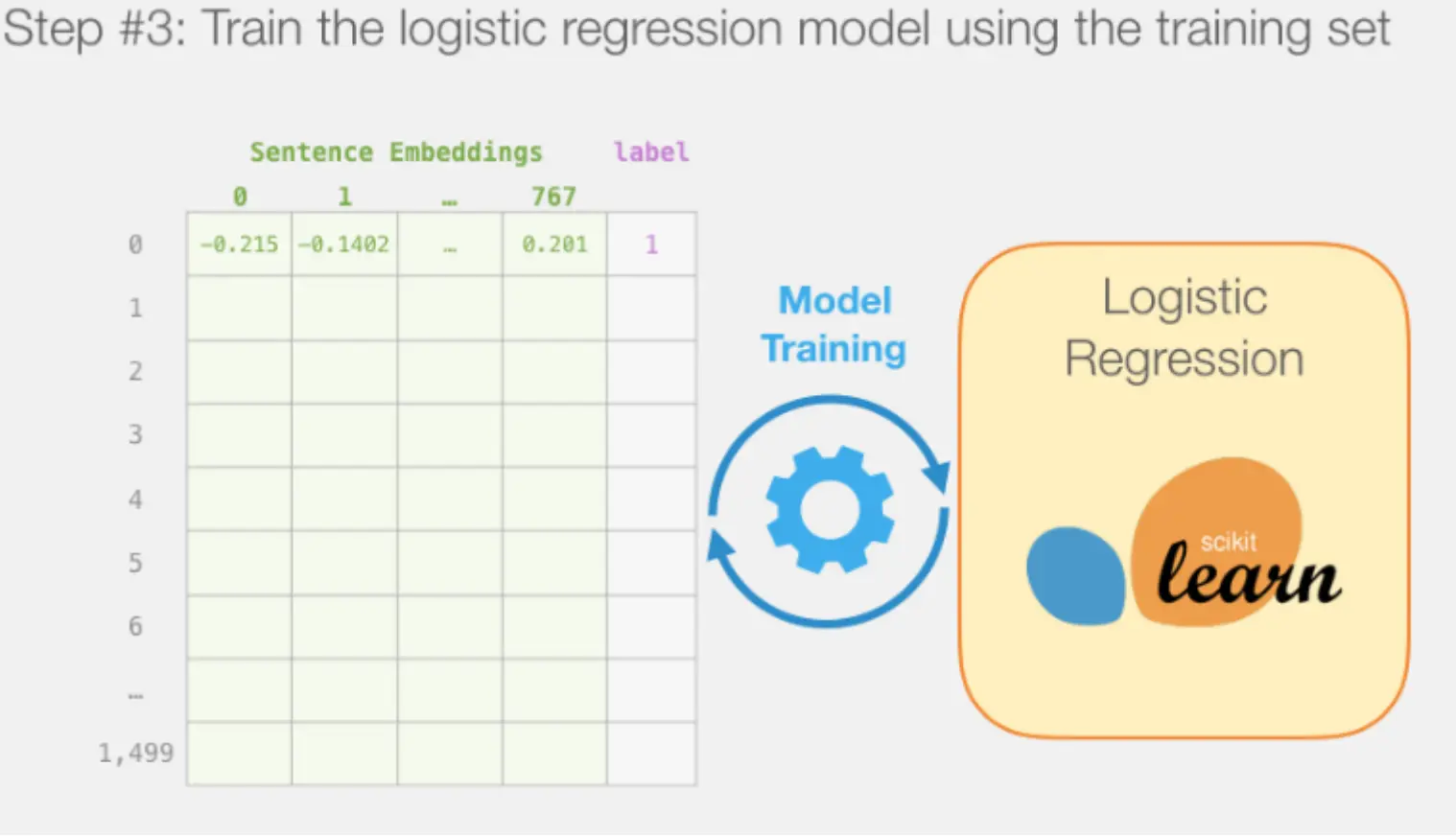
GPT2 - Decoder only
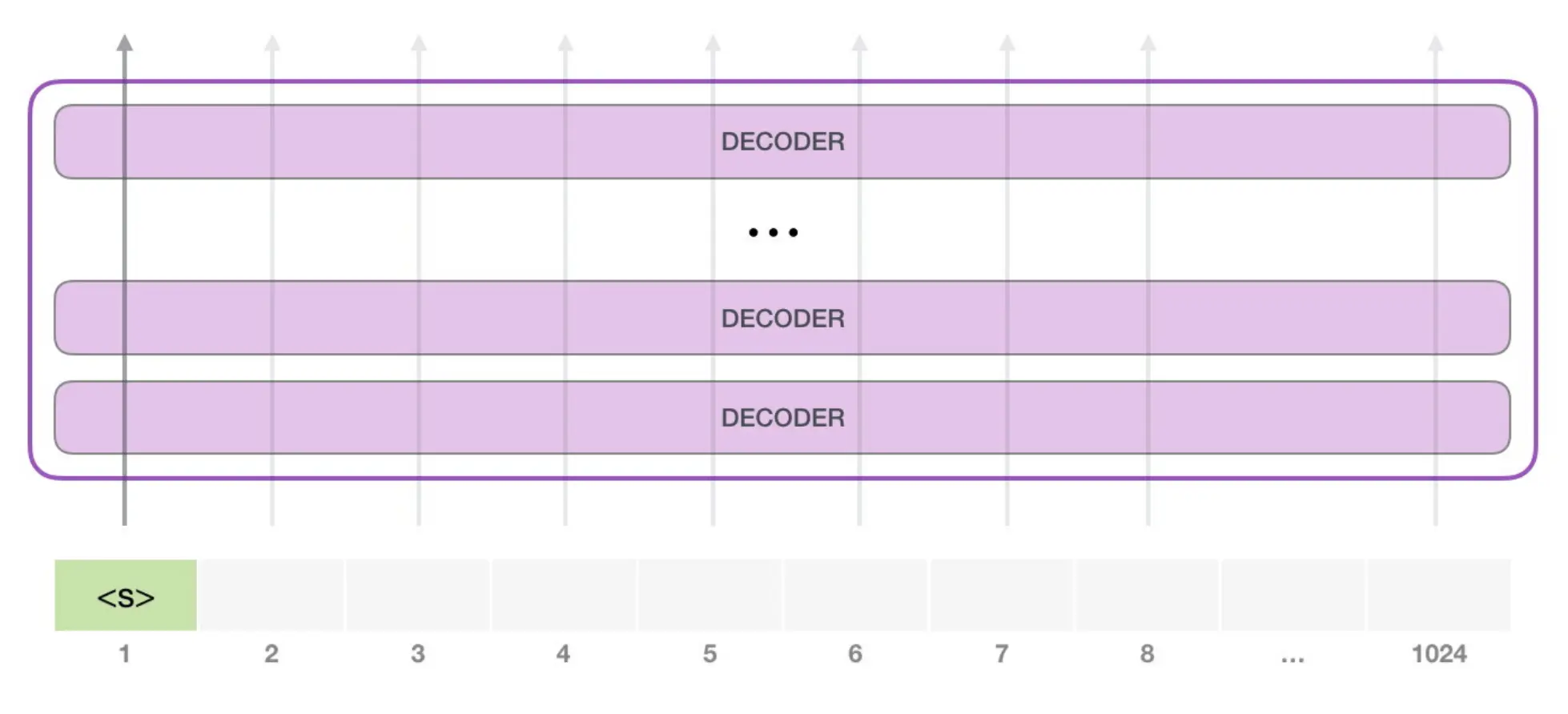
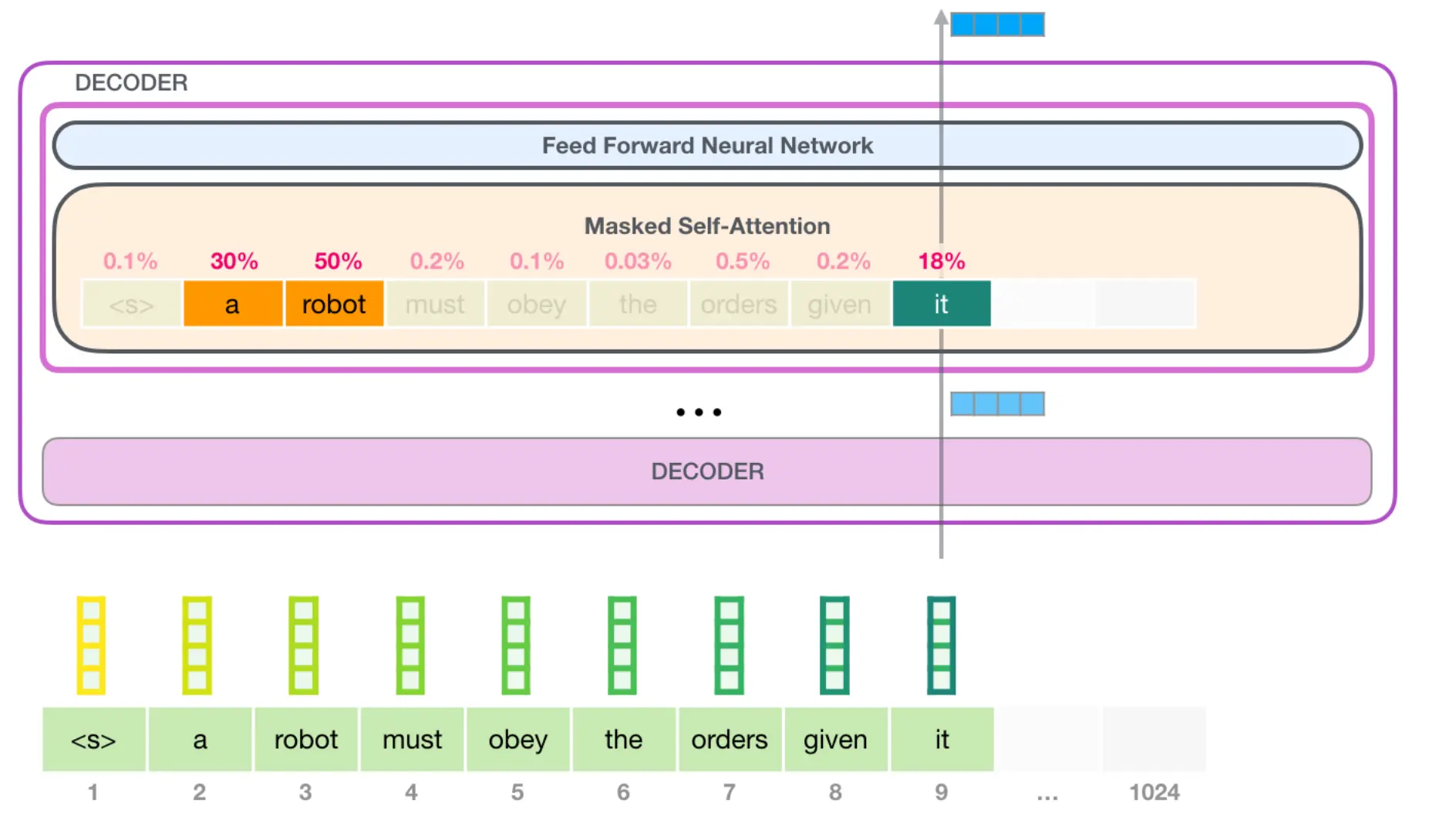
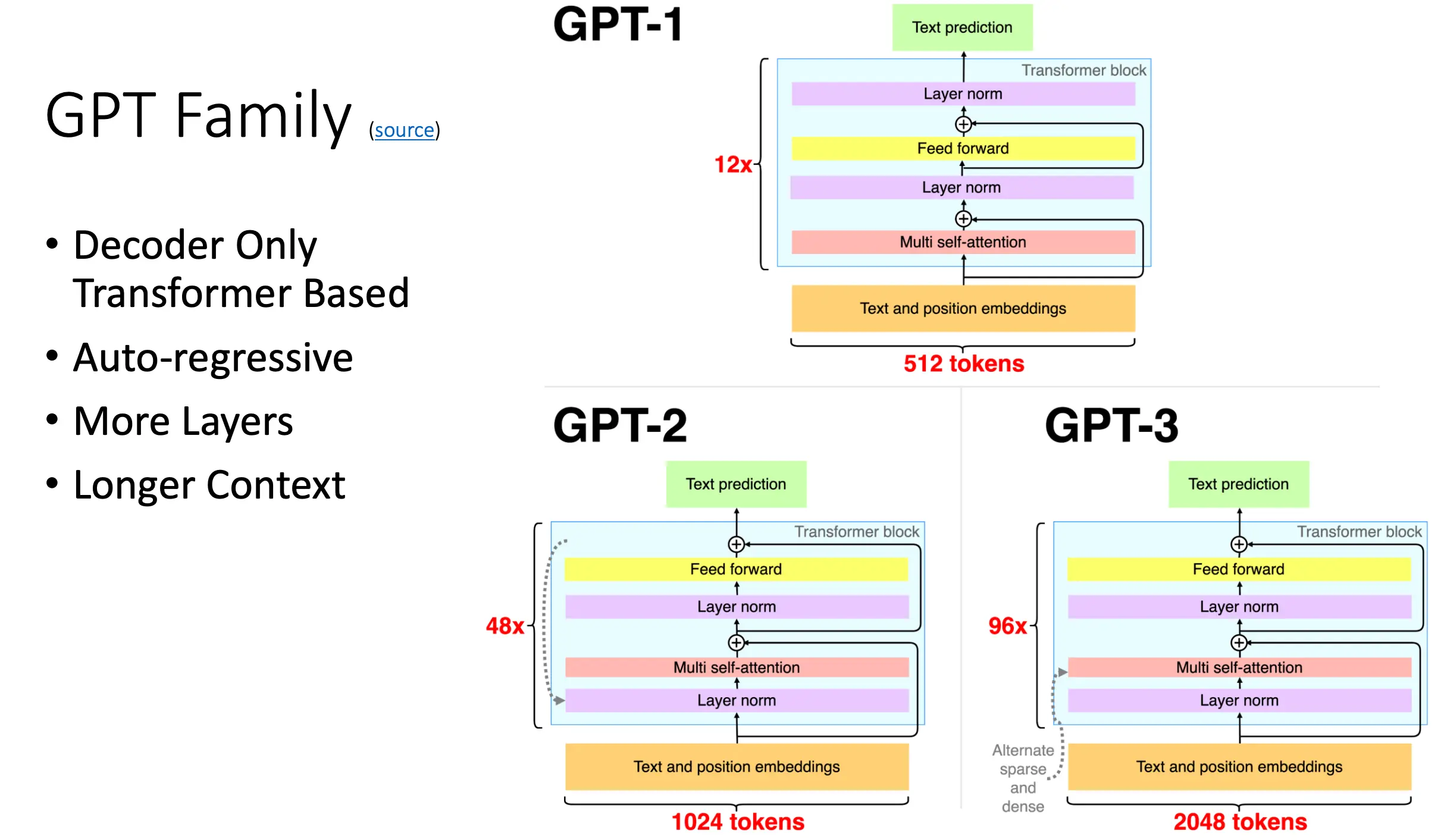
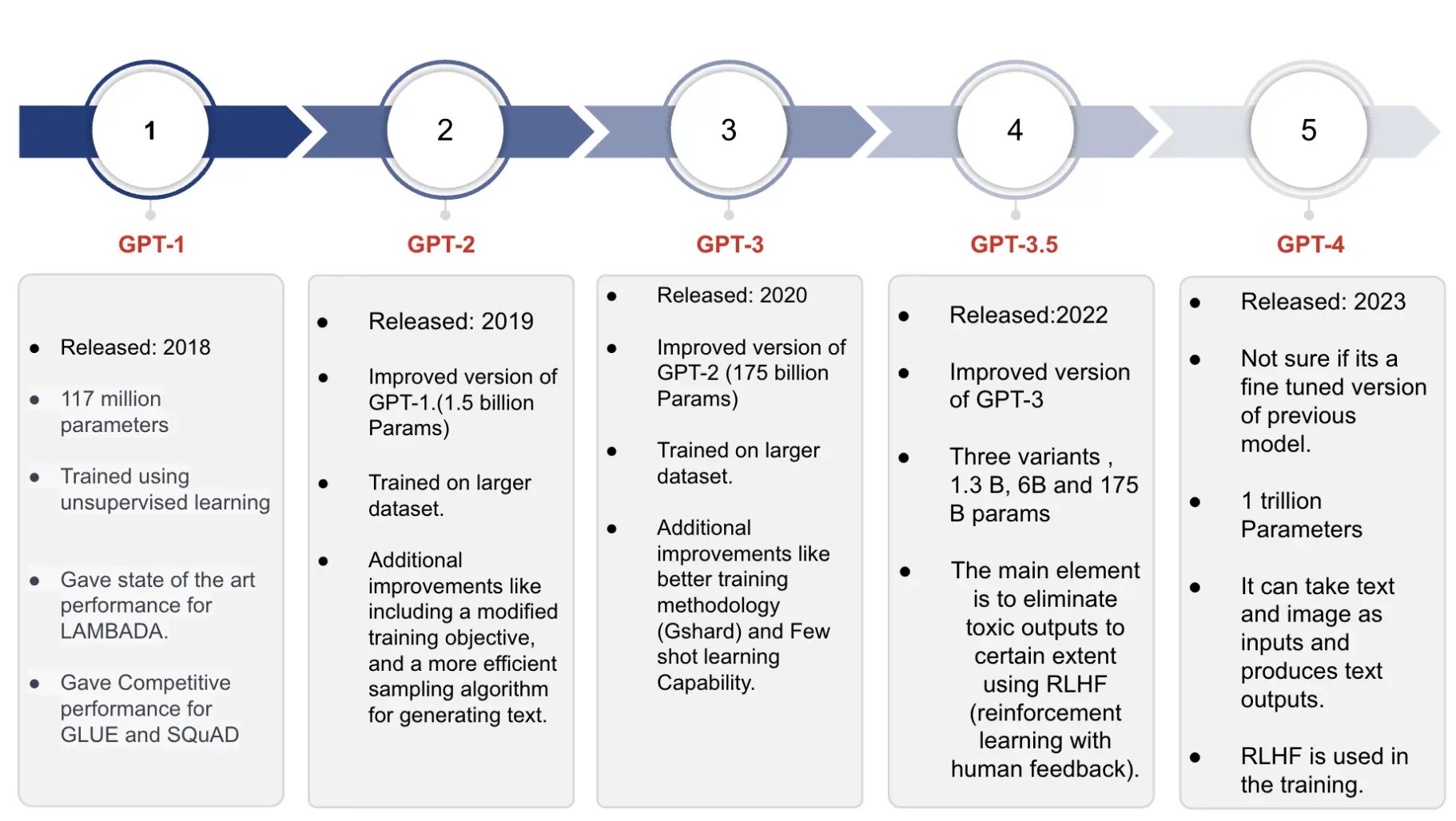
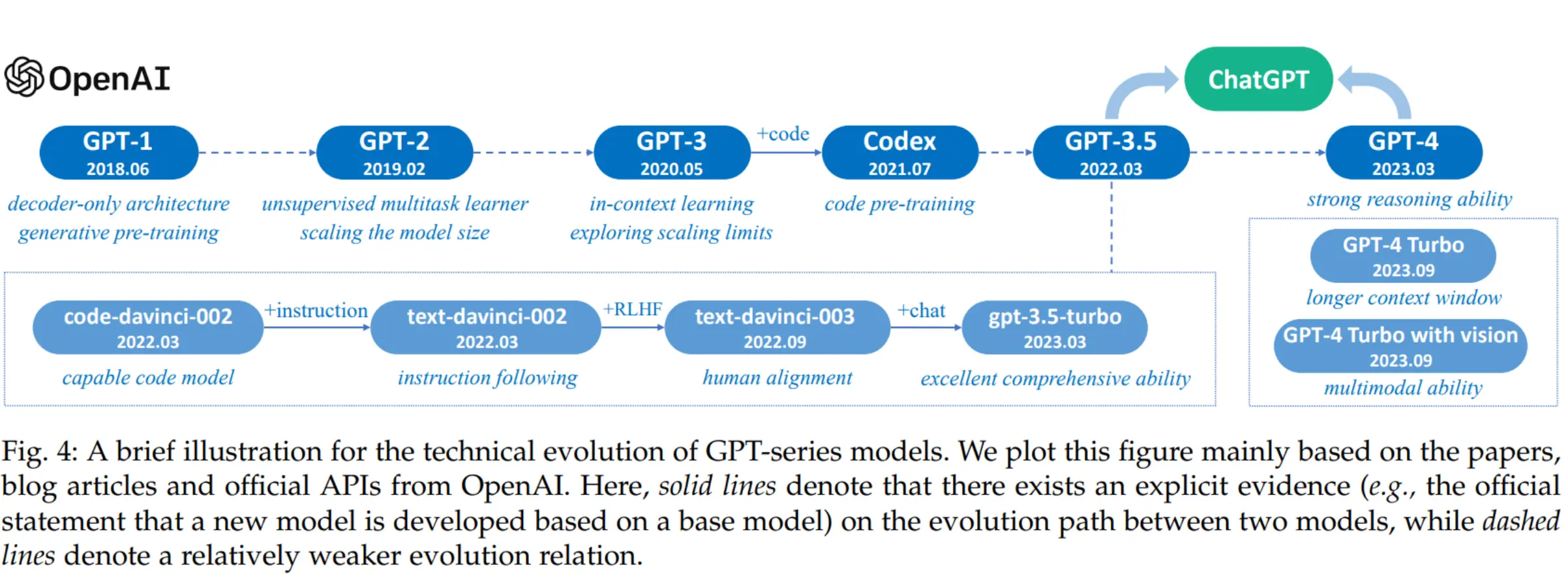
微调LM来使其适用于你的任务
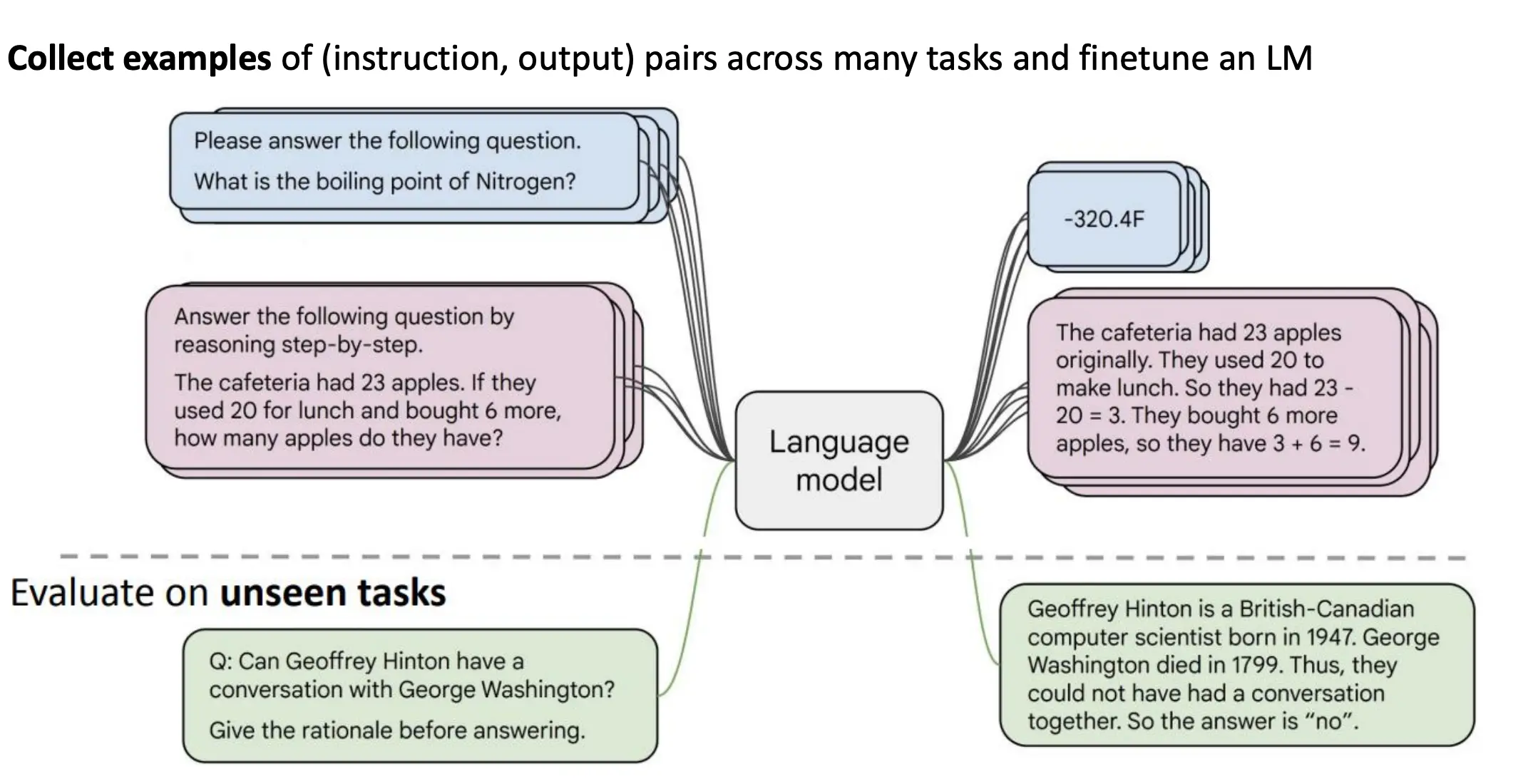
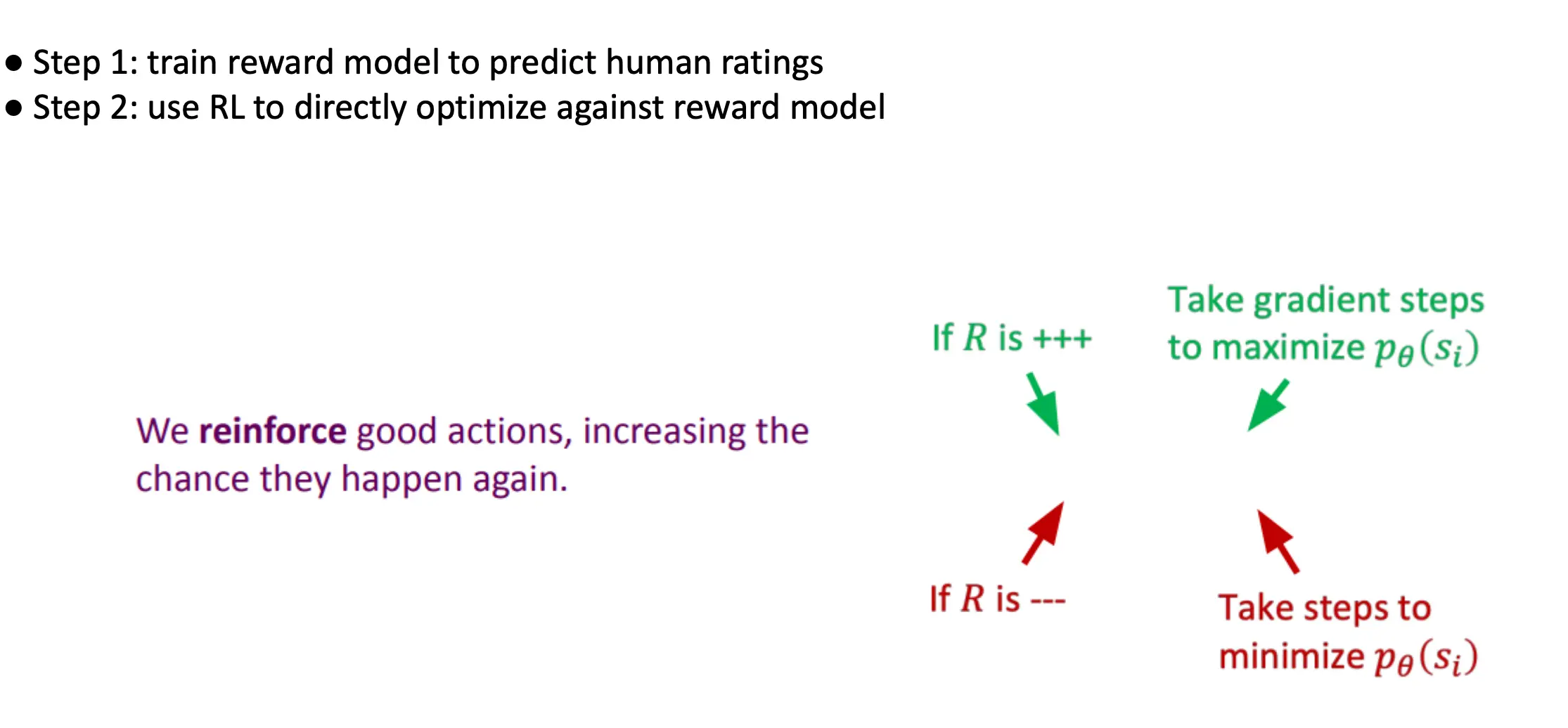
使用RL from Human Feedback (RLHF)
 LLM还可以做 • Zero-Shot Learning • One-Shot Learning • In-Context Learning
LLM还可以做 • Zero-Shot Learning • One-Shot Learning • In-Context Learning
 Larry Shi
Larry Shi